Data Science & AI
Introduction
The Sarus SDK allows the analyst to manipulate datasets with standard data science libraries. It endeavors to provide a single unified interface around the familiar NumPy, Pandas, and Scikit-Learn APIs. For instance, any user familiar with the Pandas API should feel at home with the SDK.
The general framework is the following:
The analyst writes Python code in their usual development environment (local machine, remote notebook…)
At any step along the way, to get a result, they can request the evaluation of their program
When an evaluation is requested, the SDK creates a graph of transformations based on the code. The graph of transformations corresponds to the data processing job defined by the analyst
The SDK sends the graph to the Sarus application for evaluation
The server checks if the graph of operations is authorized, with respect to the analyst’s privacy policy:
If so, the graph is evaluated on the remote data and the result is sent back to the analyst
If not, the server creates an alternative graph that complies with the privacy policy (meeting the constraints on authorized operations, privacy budget, or synthetic data access for instance). Then the server evaluates the alternative graph and sends the result back to the analyst
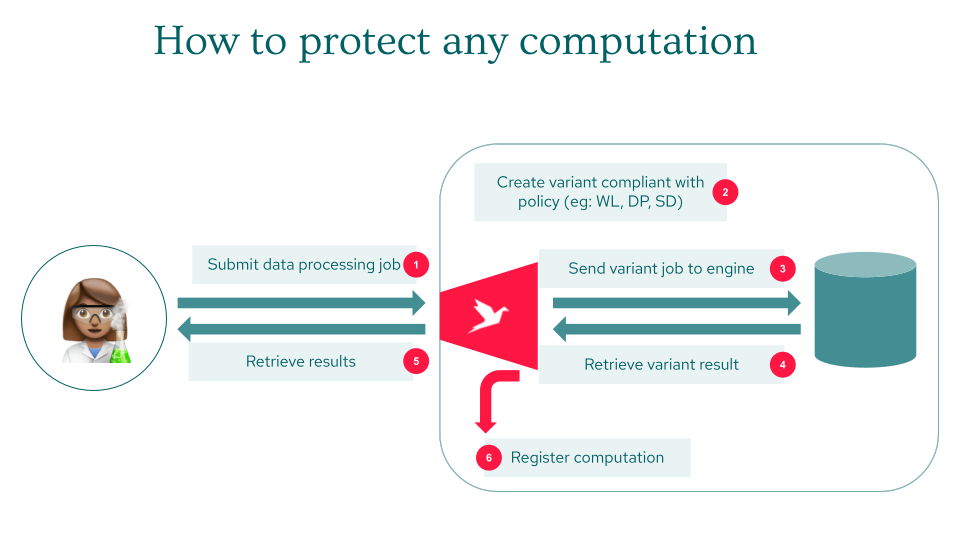
Find below a guide which presents the details of all these steps.
SDK installation and imports
To use the SDK, first the analyst needs to install the Sarus package:
>>> pip install sarus==sarus_version
Note that network security rules sometimes prevent downloading packages from PyPI (Python Package Index). If no exception car be granted for the download of an external package, please contact your Sarus account manager. NB: you want to use the SDK version corresponding to the version of Sarus installed on the server.
In order to use pandas or numpy packages on the remote dataset, it is necessary to load the corresponding API from the Sarus SDK:
>>> import sarus.pandas as pd
>>> import sarus.numpy as np
>>> from sarus.sklearn.compose import ColumnTransformer
Dataset selection
Once the library is installed, the analyst can connect to the Sarus instance using the Client object. They can check the list of datasets that were made available and select the one they want to work on:
>>> from sarus import Client
>>> client = Client(url="https://your_url",
email = "your_email@example.com",
password = "your_password"
)
>>> client.list_datasets()
[<Sarus Dataset slugname=census id=1>,
<Sarus Dataset slugname=dataset_name id=2>]
>>> dataset = client.dataset(slugname="dataset_name")
>>> dataset.tables()
[`dataset_name`, `schema`, `first_table`]
SQL analyses
The Sarus SDK can be used to run SQL analyses. The method dataset.sql() enables the analyst to run SQL queries on Sarus datasets.
List of SQL functions and operators coming soon.
The sql() method is mostly used for two things:
Run statistical SQL analyses on the data
### Run a basic SQL analysis counting the
### number of rows and the average
### amount by country
query = """
SELECT country, COUNT(*) as nb_rows, AVG(amount) as avg_amount
FROM dataset.schema.table
GROUP BY person
"""
dataset.sql(query).as_pandas()
Define an extract of the dataset to be used in a data science workflow
query = """
SELECT *
FROM dataset.schema.table
WHERE age > 56
"""
df_extract = dataset.sql(query).as_pandas()
Then, df_extract can be used as a pandas.dataframe, for example to build a ML job - see below.
Working with Pandas, Numpy, Scikit-learn…
Once the dataset is selected and the extraction of interest defined, the analyst can run analyses on the remote data using the same code they would write if the data was on their local file system. The analyst can use most of the Pandas, Numpy or Scikit-learn methods.
Supported libraries & transformations
The Sarus team continuously works on supporting more python libraries and transformations. Currently, a subset of operations of the following libraries is supported:
Pandas
Numpy
Scikit-learn
Scipy
Shap
XGBoost
Note that if the analyst uses a transformation which is not supported, the result will be computed against the synthetic data - check Understand outputs to learn more.
NB: on the Server side, there is a particular version of each library which is installed. For instance, pandas version is 1.3.5. To be sure that you will not have any incompatibilities issues, please check and install the requested version of the packages in your developing environment.
You can automatically install the requested version using the syntax pip install sarus[package_name].
Working in pandas
To work in pandas, the analyst applies the as_pandas() method to the selected table. It can be used directly on the original table of a dataset or after a .sql(). Some examples:
### as_pandas() directly on the dataset
df_transactions = dataset.table(['transactions']).as_pandas()
----------------
### as_pandas() after a .sql()
query = """
SELECT *
FROM dataset.schema.table
WHERE age > 56
"""
df_extract = dataset.sql(query).as_pandas()
Handling empty mocks error
When manipulating a Sarus dataset (for example filtering rows in a DataFrame), the SDK user may end up creating an empty object on the SDK. This means that the SDK has no data to continue its normal operation, which requires typing the object.
However, it might happen that the manipulation is still interesting because it would yield results on the actual data (not accessible in the SDK). In order to solve this issue, two solutions are available:
1. instruct the SDK to use the same type as the parent object: this is useful when you know that your operation did not alter the type of each row, just filtering rows or altering the value (but not the type) of each row. You can then use the method set_default_output_from_parent() like this:
# with the parent type
df_filtered = df[df.merchant_city == 'Paris'] # df_filtered is empty on the SDK side but can be non-empty on the server side
df_filtered.set_default_output_from_parent() # tells the SDK to use the type of the parent, which is df
df_filtered.head(10)
2. pass a pandas.DataFrame or a pyarrow.Array describing the expected result type in the operation. You can artificially add some lines in the expected result so that it’s not empty and the SDK can detect its type:
You can then use the method add_sarus_default_output() like this:
# with a dataframe object passed for the type
expected_type_row = sarus.eval(df.head(1)) # extract one row from df and convert it into a pandas.DataFrame
df_filtered = df[df.merchant_city == 'Paris'] # df_filtered is empty on the SDK side but can be non-empty on the server side
df_filtered.add_sarus_default_output(expected_type_row) # tells the SDK to use the type of variable new_row
df_filtered.head(10)
You can also use the optional parameter sarus_default_output like this:
query = """
SELECT *
FROM test_empty_mock.private.aml_transactions_2m
where merchant_city = 'Paris'
"""
remote_dataset.sql(query, sarus_default_output=expected_type_row).as_pandas()
Understand sarus.push to extract and activate data
Feature Overview
This feature enables users to push data from a dataset to a specific destination table from a data connection outside of Sarus. The process is composed of several steps:
Adding the destination database to the privacy policy to ensure the data can be pushed.
Initializing the Client: Configure the Sarus client to connect to the server.
Identifying Writable Data Connections: Check which data connections are authorized for the current user.
Describing the Destination Table: Confirm that the schema of the data you want to push matches the destination table schema.
Preparing Data for Push: Adjust your dataset if necessary to align with the destination table’s schema.
Executing the Data Push: Launch the transfer of the data to an authorized (whitelisted) destination table.
Verifying Push Status: Confirm the success of the operation and the data’s integrity in the destination table.
Step-by-step instructions are provided below.
### Step 0: Whitelist the destination table
Firsty, you need to set up the destination table towards which the data will be pushed. To do so: 1. Create a dataconnection to the database where the data will be pushed; 2. Then, go to the Admin UI, in the Privacy Policies ; 2. Enable Whitelisting by checking the box ; 3. Add the below line to the box that opens:
Where the destination_schema and the destination_table are the schema and the table you want to push the data to.
Create the privacy policy
Go to your dataset and in the Access Rules tab and give access to the proper user with this new privacy policy.
### Step 1: Initialize the Sarus Client
Then, in a Python environment, set up the Sarus client:
client = Client(
url="http://localhost",
email="analyst@example.com",
)
client.list_datasets()
### Step 2: Identify Writable Data Connections
Retrieve a list of data connections that are writable, i.e., whitelisted for you:
data_connections = client.list_writable_data_connections()
data_connection_name = data_connections[0].name
destination_table_name = data_connections[0].destination_table_names[0]
### Step 3: Describe Destination Tables
Before pushing data, understand the structure of the destination table to ensure compatibility:
client.describe_destination_table(data_connection_name=data_connection_name, table=destination_table_name)
### Step 4: Prepare Data for Push
Ensure your data matches the destination table’s schema (column names and types). Note that any extra columns in your data that are not present in the destination table will be dropped.
### Step 5: Push Data
Push data to the destination table, ensuring that you have the necessary permissions.
sarus.push_to_table(
wrapper_df,
data_connection_name=data_connection_name,
table=destination_table_name,
)
# Optionally, receive a UUID to track the push status
output_uuid = sarus.push_to_table(
wrapper_df,
data_connection_name=data_connection_name,
table=destination_table_name,
return_uuid=True
)
If the data are not aligned with the destination table’s schema, an error will be displayed.
### Step 6: Verify Push Status
Check if the data push was successful using the returned UUID:
status = sarus.check_push_to_table_status(output_uuid, return_status=True)
assert status.stage() == "ready"
### Errors
Error Handling: If a push attempt is made to a non-whitelisted destination, the following error will be displayed:
Your privacy policy does not allow you to push this dataspec with this data connection. Check your access rule and verify with client.list_writable_data_connections() which data connections you can use.
The list of available table destinations can be viewed using client.list_writable_data_connections(), which provides all the whitelisted data connections per the user’s privacy policy.
Understand outputs
At any step along the way, the analyst can check the value of their data processing job. They can do it explicitly by calling sarus.eval() or implicitly by using a remote object in an unsupported function (e.g. print(remote_object) will call implicitly the sarus.eval() function first, and then apply print()). It sends the computation graph to the server for evaluation. The server will make sure the graph is compliant with the privacy policy (if not it will create a compatible alternative) and send the result back to the analyst.
### Compute the mean of the column amount
mean_amount = df.transactions.amount.mean(axis=0,numeric_only=True)
sarus.eval(mean_amount)
Output:
Differentially-private evaluation (epsilon=1.90)
135.56147013575
There are 3 types of results:
Evaluated from Synthetic Data only : the result is computed using the synthetic data only. There is no additional DP mechanism being implemented and the calculation will not be accounted for the privacy budget.
Differentially-private evaluation: the result is computed using the remote real data by resorting to a differentially-private alternative of the requested graph (DP). The result of the evaluation will be noisy and the computation will be taken into account in the privacy budget.
Whitelisted: the result is using against the remote real data without any modification to the computational graph or protection.
The type of result depends on the transformations used by the analyst in their code. Transformations can have the following properties:
Supported transformation (see the list): this is all the methods and functions supported by the SDK and that can be used on remote data.
Protected-Unit Preserving (PUP) Transformation: this is a subset of the supported transformations where the protected unit is traceable in the output of the operation, which is a requirement to be able to apply subsequent differentially-private mechanisms (e.g.: apply() is PUP because the protected entity is unchanged before and after).
With DP implementation: this is a subset of supported transformations for which there is a differentially-private mechanism equivalent to this transformation (e.g.: count() has a DP mechanism).
To get DP or whitelisted results, it is necessary to use only supported transformations, otherwise the result will be computed using the synthetic data. The main way to have a DP result is when all transformations are PUP except for the last one that has a DP-implementation.
Epsilon consumption of DP results
Every DP result consumes some of the privacy budget (epsilon - see DP theory to know more). It can be specified by the analyst by setting the target_epsilon in the sarus.eval() function. the specified target_epsilon cannot be higher than the per-query limit fixed in the privacy policy by the data owner. When not specified, the consumption of a DP query is the default_target_epsilon determined by the privacy policy - the one set in the “Limit Value per query” in the Privacy Policy configuration.
If the DP budget is fully consumed or if the target_epsilon is greater than the authorized value, then the result will be computed against the synthetic data.